Publications.
Depth fuels expertise, breadth sparks innovation.

Ping-Chun Hsieh,
The Annual Conference on Neural Information Processing Systems (NeurIPS, Under Review), 2024
We propose Diffusion-Reward Adversarial Imitation Learning (DRAIL), which integrates a diffusion model into Generative Adversarial Imitation Learning (GAIL) to provide more robust and smoother rewards for policy learning, aiming to enhance the stability and effectiveness of adversarial imitation learning.
[ arXiv ]

Diffusion Imitation from Observation
Bo-Ruei Huang*,
Chun-Kai Yang*,
The Annual Conference on Neural Information Processing Systems (NeurIPS, Under Review), 2024
We propose Diffusion Imitation from Observation (DIFO), a novel adversarial imitation learning from observation framework that employs a conditional diffusion model to provide robust and data-efficient rewards for policy learning, demonstrating superior performance across various continuous control tasks.
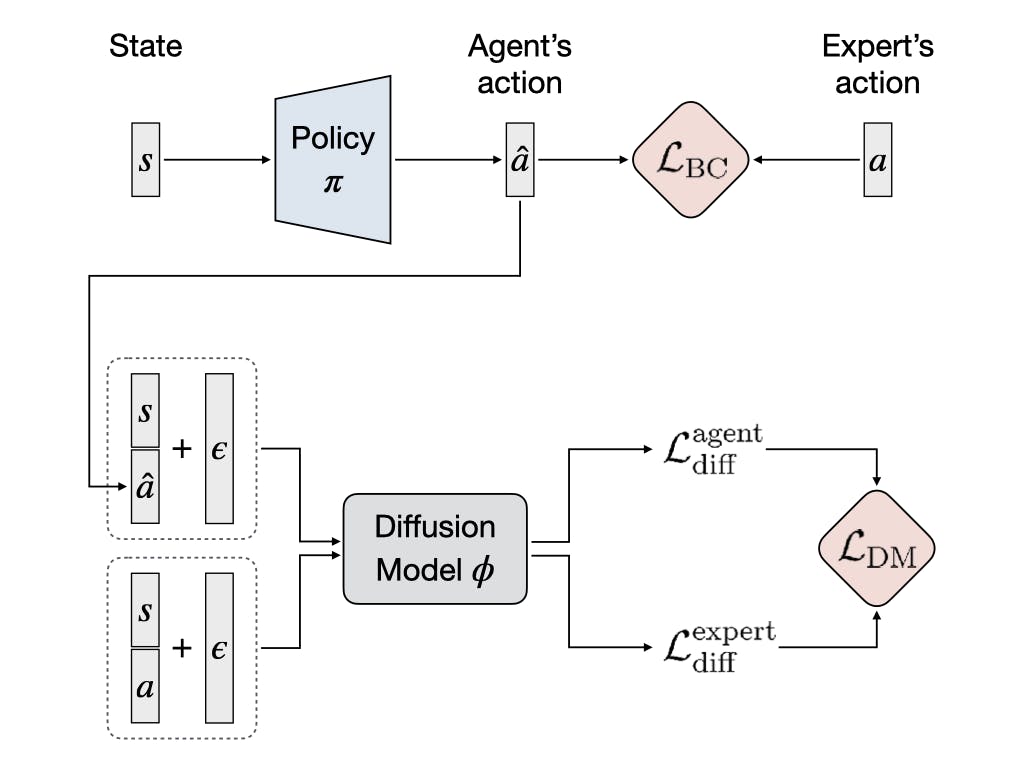
The International Conference on Machine Learning (ICML), 2024
We propose Diffusion Model-Augmented Behavioral Cloning (DBC), an imitation learning framework that leverages a diffusion model to jointly optimize behavioral cloning loss and diffusion model loss, thereby enhancing policy learning and achieving superior performance in various continuous control tasks.
[ Project Page ]
[ arXiv ]

Yuan Tseng,
Layne Berry*,
Yi-Ting Chen*,
I-Hsiang Chiu*,
Hsuan-Hao Lin*,
Max Liu*,
Puyuan Peng*,
Yi-Jen Shih*,
Hung-Yu Wang*,
Haibin Wu*,
Po-Yao Huang,
Shang-Wen Li,
David Harwath,
Yu Tsao,
Shinji Watanabe,
Abdelrahman Mohamed,
Chi-Luen Feng,
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024
We propose the AV-SUPERB benchmark that enables general-purpose evaluation of unimodal audio/visual and bimodal fusion representations on 7 datasets covering 5 audio-visual tasks in speech and audio processing.
[ Project Page ]
[ arXiv ]
[ Code ]
